前言背景
近期,经过龙芯中科与NCNN社区的共同努力,在NCNN中使用龙架构(LoongArch)向量优化实现了大部分算子,得益于龙架构向量的高效实现,优化后NCNN在平台上各项性能测试比通用实现普遍提升一倍以上。
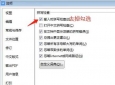
基于龙架构向量优化开启前后的NCNN各项性能对比 (竖轴为耗时高度,越高耗时越久,性能越低)
NCNN作为业界首个为移动端优化的神经网络前向计算框架,在2017年首次开源,是腾讯优图实验室第一次对外公开深度学习的研究成果。目前多应用在图像方面,例如人像自动美颜,照片风格化,超分辨率,物体识别等等。NCNN计算框架,因其高性能、无第三方依赖、跨平台支持大部分常见CNN网络的特点,是许多开发者在移动端、嵌入式设备上部署深度学习算法的首选框架。
龙架构向量优化加入NCNN生态社区
本次优化共产出3万多行代码,成果将应用于龙芯AI边缘计算场景,完成基于龙架构平台的特征识别、图像处理、人脸识别等模型的部署和推理,如门禁系统、手势识别、口罩检测等等。依托于NCNN计算框架优秀的低耦结构,开发者只需关注算子在龙架构平台上的高效实现,无需考虑整个系统结构问题,实现更高效的开发与部署工作。前期,NCNN与龙芯CPU进行了较为全面的适配和性能优化,共同打通了AI应用和国产CPU硬件间的壁垒。
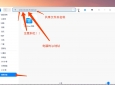
可搭载NCNN框架的龙芯AI边缘计算场景
龙芯中科将与NCNN社区保持密切合作,继续根据龙架构平台向量特点不断优化算子,推进龙架构生态成果落地更多场景、服务更多领域、欢迎社区广大开发者与龙芯中科一道共建自主开放的龙架构生态体系。
(文章来自龙芯中科,如有违权请联系删除!) |
|
|
|
|
|
|
|
|
版权说明:论坛帖子主题均由合作第三方提供并上传,若内容存在侵权,请进行举报







 私信
私信